Comme beaucoup d’entre vous le savent, j’ai écrit quelques bafouilles que j’ai voulu mettre dans un gros livre. Depuis le début (circa 2014, déjà), j’ai toujours su que je ne pourrai pas le vendre : il y a trop d’images (XKCD, Calvin & Hobbes, …) qui ne sont pas libres de droit, que pour pouvoir espérer le vendre1.
My point is : je n’ai pas envie de garder toutes ces conneries que pour moi. Et plusieurs personnes de mon entourage semblent intéressées d’y avoir accès facilement. Asciidoc (et Asciidoctor) que j’ai utilisés pour rédiger ces quelques pages peut joyeusement se convertir autant en PDF (au travers d’ Asciidoctor-pdf) qu’en HTML (avec un des backend built-in). Mon soucis est que le résultat ne me convient pas :
- La conversion en PDF ne donne pas un résulat pas super personnalisable. Il existe bien la possibilité de convertir de l’asciidoc en LaTeX, mais là aussi, on dépend beaucoup du bon vouloir de la chaîne d’outils - en passant par Docbook, puis par Apache FOP ou DBLatex, mais dans les deux cas, j’obtiens des erreurs d’interprétation rédhibitoires, qui n’aboutissent pas (oui, c’est la définition de “rédhibitoire”. Pour une fois que j’arrive à l’écrire. Deux fois.).
- Le résultat en HTML ne me convient finalement pas : il est possible de créer des “sections”, mais à condition de développer le petit script qui va séparer les différents sections (déjà créées) en plusieurs “sous-pages”. Je pensais (un peu naïvement) que ç’aurait été le comportement standard de la génération HTML, mais non.
J’ai un peu regardé les différents générateurs existants - j’aime beaucoup Hugo, que j’utilise pour le blog, et je suis tombé sur Docusaurus. La présentation me semble sympa, claire, et l’écriture est intuitive. Les assets peuvent être embarqués inline au niveau de chaque section, et on dispose d’une “double tables des matières” : une première (sur la gauche), listant l’ensemble des chapitres et sections, et une seconde (sur la droite), qui liste les différents points à l’intérieur du texte en cours de lecture.
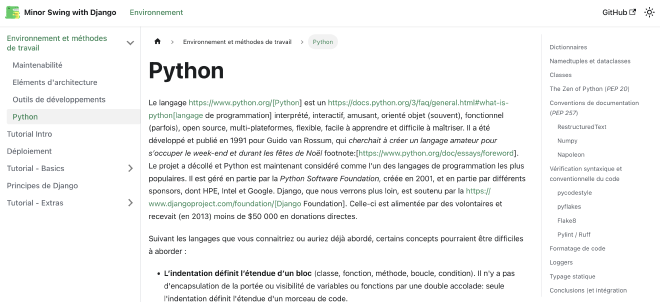
Cela va me demander du boulot (il va falloir convertir du texte Asciidoc en Markdown, réorganiser les images, …), mais le résultat pourra être constamment à jour - soit via un upload SSH, soit via des Actions Github (au hasard), avec une chouette présentation native.
J’avais déjà fait une croix sur la finitude de ce projet : j’aurai systématiquement et constamment des choses à y ajouter. Rendre ma copie aurait signifié la fin, alors que je n’ai fait qu’effleurer la surface d’un sujet qui me passionne, et que je prends plaisir à faire évoluer.
La conversion d’un document Asciidoc en Markdown peut être réalisée grâce aux deux commandes suivantes :
asciidoc -b docbook yourfile.adoc
pandoc -f docbook -t markdown_strict yourfile.xml -o yourfile.md
… que l’on peut scripter de la manière suivante :
#!/bin/bash
filename=$1
asciidoc -b docbook ${filename}
pandoc -f docbook -t markdown_strict ${filename/adoc/xml} -o ${filename/adoc/md}
-
Et de toutes façons, si j’avais dû en estimer le prix de vente, je l’aurais mis en prix libre 😌 Vu la qualité de certains des textes, j’aurais l’impression d’extorquer mes lecteurs. ↩︎