If you think good architecture is expensive, try bad architecture (Brian Foote and Joseph Yoder)
J’aurais bien du ou voulu lire ce livre il y a quelques années. Et a posteriori, il devrait faire partie de la bibliothèque de n’importe quel développeur un tant soi peu attaché à la qualité de son travail.
Une définition complète d’une application est la suivante (page 183) : « A computer program is a detailed description of the policy by which inputs are transformed into outputs ». Le niveau le plus haut (et le plus abstrait) de l’application doit être formalisé au travers des politiques, tandis que les détails concernant les choix techniques d’implémentation doivent pouvoir évoluer au fil du temps, et ne doivent en aucun cas être figés : changer de moteur de moteur de base de donnés ou ajouter un mécanisme de cache doit pouvoir être modifié sans avoir à changer le comportement déjà défini. En allant au plus loin, le système d’exploitation lui même doit presque être considéré comme un détail d’implémentation.
Le livre reste extrêmement théorique et demande, soit beaucoup d’imagination - faute d’exemples concrets -, soit déjà une certaine expérience en développement et architecture logicielle. C’est aussi pour cela qu’il est difficile de le recommander à n’importe qui : je pense qu’il sera difficile de projeter les conseils promulgués si on n’a pas au minimum rencontrer quelques unes des situations explicitées. C’est en abordant les annexes que j’ai compris l’humilité de l’auteur : les étapes du livre distillent des conseils de haut niveau par rapport à ses propres échecs professionnels, qui peuvent du coup être traduits par « ne vous plantez pas là où j’ai échoué ».
Les principes SOLID sont (évidemment) abordés (comme dans une grosse partie des livres et articles qui touchent au développement informatique), et plus que dans la définition d’une architecture adéquate, c’est surtout dans la facilité de maintenance que ces principes prouvent leur intérêt. Par exemple, une architecture ouverte et pouvant être étendue au travers de greffons n’a d’intérêt que si le développement sous-jacent tient compte de ce type de possibilité, et à condition que les gestionnaires, développeurs (et architectes) s’engagent à capitaliser sur cette architecture pour, lorsque des changements seront nécessaires par la suite, économiser du temps et améliorer la qualité. Ce point peut être résumé de la manière suivante : “Autant la création d’une nouvelle application peut être relativement facile à mettre en place, autant c’est sa maintenance qui accaparera la majorité du temps de son existence”.
Si je peux conclure (bis), l’application de ces principes de développement permettra surtout de se préparer correctement à tout ce qui pourrait arriver, sans aller jusqu’à surcharger tout développement avec des fonctionnalités non demandées (que l’on peut trouver sous l’acronym YAGNI - “You Ain’t Gonna Need It), juste « au cas ou ». Pour paraphraser une partie de l’introduction (page 1 😉), « Getting software right is hard : it takes knowledge and skills that most young programmers don’t take the time to develop. It requires a level of discipline and dedication that most programmers never dreamed they’d need. Mostly, it takes a passion for the craft and the desire to be a professional ».
Derrière une bonne architecture, il y a un investissement quant aux ressources qui seront nécessaires à faire évoluer l’application : ne pas investir dès qu’on le peut remplira lentement la case de la dette technique.
Good architecture makes the system easy to understand, easy to develop, easy to maintain and easy to deploy. The ultimate goal is to minimize the lifetime cost of the system and to maximize programmer productivity (Chapitre 15, what is architecture ?, page 137)
L’objectif est aussi de garder le plus d’options possibles, et de ne se concentrer sur les détails (le type de base de données, la conception concrète, …) que le plus tard possible, en conservant la politique principale en ligne de mire. Ceci permet de délayer les choix techniques à « plus tard », ce qui permet également de concrétiser ces choix en ayant le plus d’informations possibles. (Page 141 - what is architecture)
The longer you leave options open, the more experiments you can run, the more things you can try, and the more information you will have when you reach the point at which those decisions can no longer be deferred.
Mais plus que ça, une bonne architecture fait en sorte que le système puisse être facile à modifier, dans tous les domaines que cela pourrait impacter, « simplement » en gardant le plus d’options ouvertes que possible. Au plus le système évolue, au plus il gagne en complexité et au plus il devient difficile à maintenir maintenable. Une bonne architecture peut donc être cassée en un instant, en même temps que toutes vos intentions, simplement en n’ayant pas fait attention à certains moments clés.
Evolution de l’application ➡️ Complexité ⬆️ ➡️ Maintenabilité ⬇️
Il est primordial de rester vigilant quant aux évolutions demandées pour l’application, et il ne faut jamais oublier qu’écrire du nouveau code est toujours plus facile que d’adapter du code existant.
Principes de développement et évolution des langages #
La première valeur d’une application est son comportement : les développeurs travaillent pour faire gagner ou économiser de l’argent à ses bénéficiaires.
Au chapitre 5 (page 36), il y a un douloureux moment où l’on se rend compte qu’il était tout à fait possible de proposer un niveau d’encapsulation aussi bon en C que ce que font les langages plus récents comme Java, par exemple, en convertissant des pointeurs d’une structure vers une autre (à condition que ces deux structures suivent la même modélisation). Pour résumer ce dernier point, il était tout à fait possible de réaliser tout ce que les langages actuels peermettent et autorisent, rien qu’en respectant des conventions, ce qui était de plus en plus difficile.
En résumé, les langages OO n’apportent rien au niveau de l’encapsulation que ce que proposaient déjà des langages plus anciens ; ils apportent par contre beaucoup en terme de polymorphisme, de sécurité et de facilité de mise en place.
The fact that Object-Oriented languages provide safe and convenient polymorphism means that any source code dependency, no matter where it is, can be inverted (Chapitre 5, Object-oriented programming, page 44).
Pour résumer ce chapitre, la programmation orientée objet est “la capacité, au travers du polymorphisme, à contrôler de manière absolue les dépendances d’un système, au travers d’interfaces”.
A vrai dire, ma connaissance de la programmation orientée-objet est principalement basée sur l’expérience : le premier contact avec été réalisé en première année d’informatique, quand nous avons eu droit à un « Ce n’est pas orienté objet ! » édicté par l’un des assistant, suivi (en deuxième année) d’un « Jusqu’à présent, vous avez surtout appris le C moins moins ». Forcément, cela laisse des traces. Les principes d’encapsulation ont été plus ou moins balayés, le polymorphisme abordé théoriquement et l’héritage présenté comme le principal attrait de ce paradigme, sans réellement présenter ses autres intérêts (ou alors au travers d’exemples succincts).
Tests #
We show correctness by failing to prove incorrectness, despite our best efforts (Chapitre 4 - Structured Programming, page 31) : A program can be proven incorrect by a test, but it cannot be proven correct. All that tests can do, after sufficient testing effort, is allow us to deem a program to be correct enough for our purposes.
Une remarque aussi est que la première release est la plus partie la plus simple du développement et ne nécessite pratiquement aucune maintenance ou considération pour les clients ou utilisateurs. Les tests nous placent (nous, les développeurs) comme clients ou utilisateurs de notre propre travail. Si une partie de l’application est trop complexe que pour être testée, elle pourra être décomposée en plus petites unités qui pourront être plus facilement testables.
Tests are part of the system (the boundary, ch 28, page 250)
Le fait que les tests soient généralement isolés du reste du système laisse à penser qu’ils en sont totalement indépendants, ce qui est faux : les tests appellent des méthodes et fonctions internes à ce système, et y sont donc intimement couplés. Il est également important que ces tests ne rendent pas le système rigide : si le fait de changer un concept d’architecture, casse trop de tests, le développeur bottera en touche et ne changera finalement rien. La solution consiste à modéliser le système en vue de pouvoir être testé.
Règles métiers #
Les règles métiers sont définies selon deux axes :
- Celles qui sont critiques au métier (critical business rules) et qui existeraient même sans un processus (ou une tentative) d’automatisation,
- Toutes les autres.
C’est également le cas pour les données, puisqu’il existe des données suffisamment critiques que pour exister sans nécessiter un processus d’automatisation. A cela, nous pouvons ajouter la définition d’une « entité », qui correspond à un ensemble de règles critiques appliquées à des donnés critiques. L’interface de cette entité consiste en l’ensemble des fonctions qui implémentent les règles métiers qui agissent sur les données embarquées.
Les « use cases » sont la définition et contraintes appliquées à un processus automatisé, et qui permettent à l’entreprise d’économiser ou de gagner de l’argent. Un « use case » est donc la description de la manière dont un système automatisé va être utilisé. Attention que les use cases ne décrivent pas comment le système apparait aux utilisateurs, mais plutôt les règles qui gouvernent les interactions entre les utilisateurs et les entités (Chapitre 20, business rules, page 193). Il est important que le use cases soit agnostique quant aux détails de l’application.
Frameworks #
Frameworks are tools to be used, not architectures to be conformed to. Your architecture should tell readers about the system, not about the frameworks you used in your system. If you are building a health care system, then when new programmers look at the source repository, their first impression should be, « oh, this is a health care system ». Those new programmers should be able to learn all the use cases of the system, yet still not know how the system is delivered. (Page 199)
Comme vu dans les règles métiers, les entités encapsulent les règles critiques de l’entreprise. Lors de la conception d’une application, chaque entité doit correspondre aux objets métiers de l’application, qui encapsulent les règles les plus générales et haut niveau, sans jamais être gênées par une présentation en pagination ou un niveau de sécurité. Aucun changement opérationnel ne devrait affecter une entité.
Pour une application réalisée avec Django, ces entités correspondent déjà aux modèles. Le problème est qu’elles sont déjà liées à la base de données, même si cette base n’est pas encore connue. Ce que Django réalise, c’est une modélisation initiale à partir d’une structure organisationnelle. Dans une certaine mesure, la base de données reste donc bien un détail d’implémentation, mais jusqu’à un certain point, dont il faudra tenir compte. Il y aura ici un intérêt tout particulier à définir des modèles proxy ou à passer par DRF, dans la mesure où ceci va permettre de définir des frontières applicatives, et permettre ainsi de passer des structues simplifées.
Ces frontières permettent également de se débarrasser facilement d’une application legacy, puisqu’il suffirait de modifier un type de processus pour remplacer l’intégralité de l’interface, après avoir réimplémenté l’ensemble des méthodes et fonctions nécessaires à son fonctionnement.
When any of the external parts of the system become obsolete, such as the database, or the web framework, you can replace those obsolete elements with a minimum of fuss. (Page 209).
Avec Django, la difficulté à se passer du framework va consister à basculer vers « autre chose » et a remplacer chacune des tentacules qui aura poussé un peu partout dans l’application, ce qui demandera énormément de travail - voire, pourrait être impossible à moins de recommencer une nouvelle version en utilisant d’autres technologies.
De manière plus générale, aucune donnée ne doit être placée « manuellement », que ce soit un menu ou une information affichée : un bouton à cliquer pour l’utilisateur, masquer ou griser une donnée, … Tout ceci doit faire partie de la couche de présentation.
Pour résumer cette partie, une application doit être :
- Indépendance d’un framework,
- Testable,
- Indépendante de l’interface utilisateur,
- Indépendante du moteur de base de données,
- Indépendante de n’importe quelle structure de données externes (type INAMI).
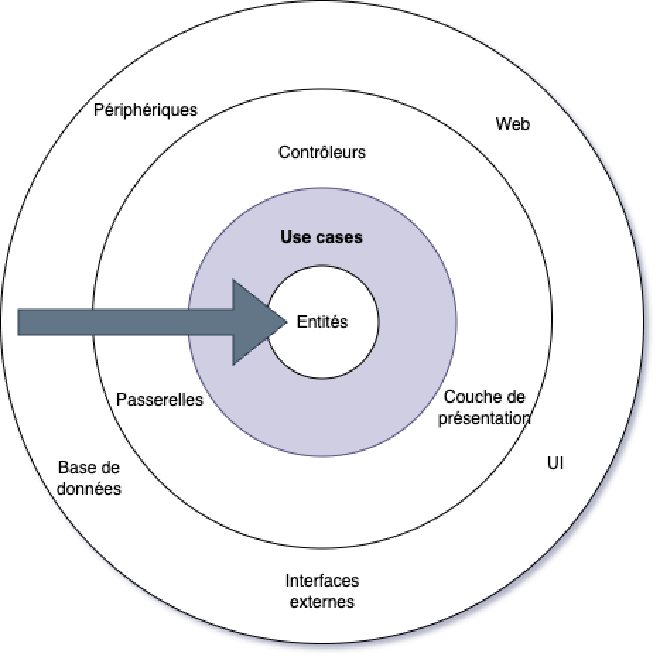
Vous pouvez envisager vos tests comme étant les cercles les plus éloignés du centre de l’architecture : rien ne doit dépendre de vos tests, tandis que les tests dépendent systématiquement d’autres composants du système. Les cercles les plus à l’intérieur de l’architecture représentent les politiques (pages 203 et 250).
SOLID #
- SRP - Single responsibility principle
- OCP - Open-closed principle
- LSP - Liskov Substitution
- ISP - Interface ségrégation principle
- DIP - Dependency Inversion Principle
En plus de ces principes de développement, il faut ajouter des principes architecturaux au niveau des composants :
- Reuse/release équivalence principle,
- Common Closure principle,
- Common Reuse principle.
La même réflexion sera appliquée au niveau architectural, et se basera sur ces mêmes primitives.
Single Responsibility Principle #
A module should be responsible to one and only one actor.
Traduit autrement, le Single Responsibility Principle nous dit qu’une classe ne devrait pas contenir plus d’une raison de changer. Le principe de responsabilité unique diffère d’une vue logique qui tendrait intuitivement à centraliser le maximum de code: à l’inverse, il faut plutôt penser à différencier les acteurs. Un exemple donné consiste à identifier le CFO, CTO et COO qui ont tous besoin de données et informations relatives à une même base de données des membres du personnel, mais ils ont chacun besoin de données différents (ou en tout cas, d’une représentation différente de ces données). Nous sommes d’accord qu’il s’agit à chaque fois de données liées aux employés, mais elles vont un cran plus loin et pourraient chacune nécessiter des ajustements spécifiques en fonction de l’acteur concerné.
Déjà ici, il est question de définir un modèle (une forme de Data Transfer Object), qui sert principalement à communiquer des structures d’informations. En parallèle, il est alors proposé d’avoir trois structures en fonction des trois acteurs définis ci-dessus.
Au niveau des composants, le SRP deviendra le Common Closure Principle. Au niveau architectural, il évoluera vers la définition des frontières (boundaries).
L’idée sous-jacente est simplement d’identifier dès que possible les différents acteurs, en vue de prévoir une modification qui pourrait être demandée par l’un ou l’autre d’entre eux, et qui pourrait avoir un impact sur les données utilisées par les autres.
Open Closed Principe #
L’objectif est de rendre le système facile à étendre, en évitant que l’impact d’une modification ne soit trop grand.
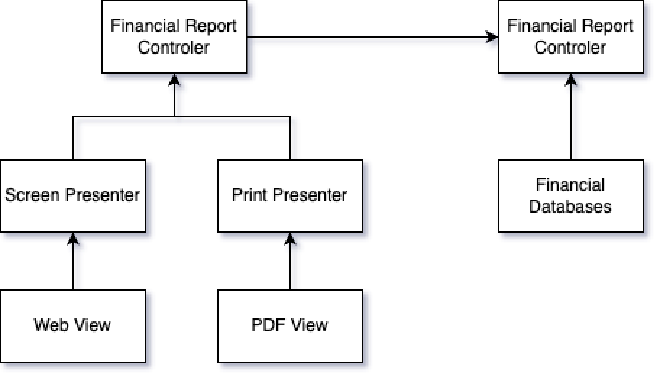
L’exemple pratique parle de lui-même : des données doivent être présentées dans une page web. Et demain, ce sera dans un document PDF. Et après demain, ce sera dans un tableur Excel.
La source de ces données restera systématiquement la même, au travers d’une couche de présentation, mais la mise en forme diffèrera à chaque fois. L’application n’a pas à connaître les détails d’implémentation : elle doit juste permettre une forme d’extension, sans avoir à appliquer une modification (ou une grosse modification) sur son cœur.
Liskov Substitution Principle #
Ce chapitre-ci (le 9) est sans doute celui qui est le moins complet. Je suis d’accord avec les exemples donnés, dans la mesure où la définition concrète d’une classe doit dépendre d’une interface correctement définie (et que donc, faire hériter un carré d’un rectangle, n’est pas adéquat dans le mesure où cela induit l’utilisateur en erreur), mais il y est aussi question de la définition dun style architectural pour une interface REST, mais sans donner de solution…
Interface Segregation Principle #
L’objectif est de limiter la nécessité de décompiler en n’exposant que les opérations nécessaires à l’exécution d’une classe, et pour éviter d’avoir à redéployer l’ensemble d’une application pour un changement minime.
En Python, ce comportement n’est pas vraiment d’application, puisqu’il est inféré lors de l’exécution. De manière générale, les langages dynamiques sont plus flexibles et moins couplés que les langages statiquement typés, pour lesquels il serait possible de mettre à jour une DLL ou un JAR sans que cela n’ait d’impact sur le reste de l’application.
The lesson here is that depending on something that carries baggage that you don’t need can cause you troubles that you didn’t except.
(et j’aime à rappeler que c’est vrai partout, et pas uniquement en développement logiciel 😉)
Dependency Inversion Principle #
The dependency inversion principle tells us that the most flexible systems are those in which source code dependencies refer only to abstractions, not to concretions.
L’objectif est que les interfaces soient stables, afin de réduire au maximum les modifications qui pourraient y être appliquées.
En termes architecturaux, ce principe définira une séparation claire au niveau des frontières, en inversant le flux de dépendance et en faisant en sorte (par exemple) que les règles métiers n’aient aucune connaissance des interfaces graphiques qui les exploitent. Ces interfaces pouvant être desktop, web, … Ceci n’a pas vraiment d’importance. Cela favorise une certaine immunité entre chacun des composants.
The database is really nothing more than a big bucket of bits where we store our data on a long term basis (Chapitre 30, page 281)
Du point de vue de la conception logicielle, nous ne devons pas nous soucier de la manière dont les données sont stockées, s’il s’agit d’un disque magnétique, de mémoire vive, … En fait, on ne devrait même pas savoir ou tenir compte du tout s’il y a du matériel spécifique.
Pour les composants #
Les principes de développement peuvent être appliqués au niveau des composants, mais toujours en faisant attention qu’une fois que les frontières auront été implémentées, elles seront coûteuses à maintenir. Il ne s’agit cependant pas d’une décision à réaliser une seule fois, puisque cela peut être réévalué.
This is not a one time decision. You don’t simply decide at the start of a project which boundaries to implement and which to ignore. Rather, you watch. You pay attention as the system evolves. You note where boundaries may be required, and then carefully watch for the first inkling of friction because those boundaries don’t exist. At that point, you weight the costs of implementing those boundaries versus the cost of ignoring them and you review that decision frequently. Your goal is to implement the boundaries right at the inflection point where the cost of implementing becomes less than the cost of ignoring.
En résumé, il est nécessaire de projeter la capacité à s’adapter tout en minimisant la maintenance globale, tout en pesant le pour et le contre.
Il est fréquent qu’il existe une implémentation facile et rapide à proposer dès le début, mais que celle-ci n’autorise aucune adaptation. A la première demande, l’architecture se plantera complètement sans aucune malléabilité.
Reuse/release Equivalence Principle #
Classes and modules that are grouped together into a component should be releasable together (Chapitre 13, Component Cohesion, page 105)
Common Closure Principle #
(= l’équivalent du Single Responsibility Principle, mais pour les composants)
If two classes are so tightly bound, either physically or conceptually, that they always change together, then they belong in the same component.
La définition exacte devient celle-ci : « Gather together those things that change at the same times and for the same reasons. Separate those things that change at different times or for different reasons ».
Common Reuse Principle #
… que l’on résumera ainsi: « don’t depend on things you don’t need » 😘 Au niveau des composants, au niveau architectural, mais également à d’autres niveaux.
Acyclic Dependency Principle #
TBC
Stable Dependency Principle #
(Stable dependency principle) qui définit une formule de stabilité pour les composants, en fonction de sa faculté à être modifié et des composants qui dépendent de lui : au plus un composant est nécessaire, au plus il sera stable (dans la mesure où il lui sera difficile de changer). En C++, cela correspond aux mots clés #include. Pour faciliter cette stabilité, il convient de passer par des interfaces (donc, rarement modifiées, par définition).
Stable Abstraction Principle #
(= Stable abstraction principle) pour la définition des politiques de haut niveau vs les composants plus concrets. SAP est juste une modélisation du OCP pour les composants: nous plaçons ceux qui ne changent pas ou pratiquement pas le plus haut possible dans l’organigramme (ou le diagramme), et ceux qui changent souvent plus bas, dans le sens de stabilité du flux. Les composants les plus bas sont considérés comme volatiles.
Développements #
A software system that is hard to develop is not likely to have a long and healthy lifetime (Chapitre 15, what is architecture ?, page 137)
En ayant connaissance de toutes les choses qui pourraient être modifiées par la suite, l’idée est de pousser le développement jusqu’au point où un service pourrait être nécessaire. A ce stade, l’architecture nécessitera des modifications, mais aura déjà intégré le fait que cette possibilité existe. Nous n’allons donc pas jusqu’au point où le service doit être créé (surtout s’il peut ne jamais être nécessaire), ni à l’extrême au fait d’ignorer qu’un service pourrait être nécessaire, mais nous aboutissons à une forme de compromis. Avec cette approche, les composants sont déjà découplés au niveau du code source, ce qui pourrait s’avérer suffisant jusqu’au stade où une modification ne pourra plus faire reculer l’échéance.
En terme de découpe, les composants peuvent l’être aux niveaux suivants :
- Code source,
- Lors du déploiement, grâce à des DLL, JAR, librairies liées, … Voire au niveau des theads ou processus.
- Services.
A noter que les services et les « architectures orientées services » ne sont jamais qu’une définition d’implémentation des frontières, dans la mesure où un service n’est jamais qu’une fonction appelée au travers dun protocole (REST, SOAP, …). Une application monolotihique est tout aussi fonctionnelle qu’une application découpée en microservices (“Services: great and small”, page 243).
Déploiements #
To be effective, a software system must be deployable. The higher the cost of deployements, the less useful the system is. A goal of a software architecture, then, should be to make a system that can be easily deployed with a single action. Unfortunately, deployment strategy is seldom considered during initial development. This leads to architectures that may be make the system easy to develop, but leave it very difficult to deploy (Chap 15, page 137).
Une bonne architecture ne doit pas dépendre de dizaines de petits scripts éparpillés sur le disque. L’objectif est un déploiement rapide et maintenable. Ceci peut être atteint au travers d’un partitionnement correct des différents composants, incluant le fait qu’on composants principal s’assure que chaque sous-composant est correctement démarré, intégré et supervisé.
Conclusion #
Pour conclure :
The only way to go fast, is to go well.