Monitoring is the action of observing and checking the behavior and outputs of a system and its components over time.
Livre très, très chouette avec plusieurs exemples concrets et pratiques, utiles, et qui aborde les sujets suivants :
- My monitoring sucks. What shoud I do about it ?
- My monitoring seems OK, but I know I can do better. WHat should I be thinking about ?
- My monitoring is noisy and no one trusts it. How can I permanently fix it ?
- What stuff is the most important to monitor ? Where do I even start ?
Anti-patterns #
An anti-pattern is something that looks like a good idea, but which backfires badly when applied. – Jim Coplien
Pour résumer les anti-patterns :
- Ne soyez pas obsédés par un outil en particulier, mais plutôt parce qu’il vous permettra de réaliser,
- Le monitoring ne doit pas être la responsabilité d’une seule et même personne, mais d’une adhésion plus globale, où chacun est responsable de son bon fonctionnement et de son évolution,
- Un bon monitoring est plus qu’une simple checklist,
- Le monitoring ne permet pas de réparer les choses qui sont naturellement cassées - typiquement, une application mal développée restera mal développée, même avec un bon monitoring,
- Le manque d’automatisation est un bon moyen de rater un point essentiel.
Définition de l’infrastructure #
Après avoir entendu que “Google utilise ” ou “Sponsorisé par AirBNB”, on peut être tenté de vouloir faire la même chose, et il est alors facile d’oublier les capacités réelles de l’outil en question ou son adéquation avec vos désidérata. Quelle que soit la solution choisie, elle nécessitera un minimum d’effort pour être mise en place, et aucune solution existante ne pourra être considérée comme une silver bullet et une solution out-of-the-box ne fonctionnera que pour un nombre minimal de cas.
Le nombre d’outils que vous utilisez ne deviendra un problème que si ces outils ne peuvent pas travailler ensemble ou ne peuvent mettre leurs données en corrélation. Il est préférable de disposer d’outils distincts (choisis consciencieusement) et faiblement couplés, mais partageant leurs données : tant qu’il n’y a pas d’overlap, nous pouvons en ajouter autant que nous le souhaitons. L’important est de choisir des outils qui soient composables et qui puissent discuter entre eux. L’ensemble de ces outils deviendra une “plateforme de monitoring”, qui correspondra à vos besoins précis. Quelques exemples sont donnés, comme Sensu, Graphite, LogStash ou CollectD.
Dans la même veine, les équipes apprécieront d’utiliser des outils qui leur permettent de résoudre leurs problèmes, plutôt que d’être forcées d’utiliser des plateformes relativement pauvres, dans un but de “consolidation des outils”. Pour que le monitoring fonctionne comme il se doit, il est nécessaire de rendre tout le monde responsable de son bon fonctionnement - cf. un des principes du mouvement DevOps : monitorer correctement une infrastructure n’est pas un travail, mais une compétence, et il convient que chacun y adhère jusqu’à un certain niveau. Ceci n’exclut pas d’avoir une équipe qui batisse le système (ce qu’on appelle une observability team), mais il convient vraiment que chacun soit responsable de ce qui tourne en production.
Quelle que soit la solution choisie, orientez-vous vers l’achat ou la location d’un service, et non pas sa construction : préférez avec une solution SaaS, dont les composants pourront être rappatriés ultérieurement vers une infrastructure locale, lorsque le besoin s’en fera resentir. Construire une solution reviendrait grosso modo à 35 000€ en frais d’ingénierie - sans compter qu’il est probable de ne pas avoir les compétences nécessaires sous la main - auxquels il conviendra d’ajouter 20% / an de frais de maintenance. Une solution SaaS reviendra - dans le pire des cas - à 9000€ / an, sans parler qu’une réarchitecture pourra être nécessaire tous les 3-4 ans, en fonction des changements nécessaires et des évolutions de l’industrie.
Rassembler les informations à un seul endroit peut être une aide à la gestion d’incidents.
Composants d’un service de monitoring #
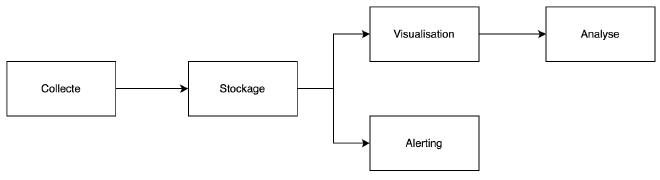
Un service de monitoring dispose de cinq facettes :
- La collecte de données,
- Le stockage de données,
- La visualisation,
- L’analyse et le reporting,
- L’alerting.
Le logging peut être vu comme un ensemble des étapes de collecte, de stockage et d’analyse des journaux.
Collecte #
La collecte de données fonctionne selon deux modes : push ou pull.
- Dans le modèle pull, un serveur central viendra interroger chaque noeud séparément, pour lui demander des informations à propos de lui-même. Un autre mode de fonctionnement propose de définir un endpoint de santé (type
/health), qui donnera des métriques et un indice de santé de chacun des composants ou modules utilisés, et qui pourra être remonté lors de la collecte. - En mode push, c’est le client lui-même qui envoie ses propres informations. Un outil pratique (re)connu est Collectd, qui fonctionne très bien sur une architecture distribuée.
Il existe deux types de données :
- Les métriques, dont les deux représentations possibles sont les compteurs (qui correspondent à des données qui croissent continuellement, comme l’odomètre dans une voiture ou le nombre de visiteurs) et les valeurs ponctuelles (mais qui ne donnent aucune information par rapport à la valeur précédente - comme une jauge).
- Les logs ou journaux, qui sont essentiellement des données textuelles associées à un horodatage. Ces logs manquent parfois de structure ou de sémantique, mais peuvent s’avérer utiles, surtout s’ils sont consommés par des humains. Une idée consiste à structurer ces journaux (par exemple, au travers d’un format JSON). Dans une architecture distribuée, le plus simple semble être d’utiliser du log forwarding (par exemple, grâce à Syslogd). Ceci rejoint également les 12-facteurs, qui conseille de traiter les journaux applicatifs comme des flux d’informations.
⚠️ Il est conseillé de disposer d’agents de supervision sur chacun de nos serveurs : la charge sera minime (par rapport à ce qu’une architecture moderne est capable de supporter), alors qu’un monitoring sans agent actif (🤭) sera particulièrement inflexible et ne vous donnera jamais la finesse et le niveau de visibilité que vous pourriez désirer.
Entre UDP et TCP, visez TCP :
- UDP permet de gérer des cas types “last dying breath”, pour que le serveur envoie ses logs juste avant de crasher. Dans la majorité des cas, ce problème n’en est pas vraiment un : résolvez pour les problèmes que vous rencontrez maintenant, et pas ceux que vous pourriez avoir plus tard.
- TLS exige un protocol TCP ; et quand on utilise des plateformes SaaS, le chiffrement n’est pas une option.
Sur des environnements *nix, utilisez syslog : soit en mode push (l’application envoie directement ses logs vers syslog), soit en mode pull (syslog vient ingérer lui-même le contenu des journaux sur disque).
Stockage #
Autrefois, nous utilisions surtout grep sur des fichiers sur disque, mais c’est une solution (un peu…) sous-optimal et il n’est pas possible d’en extraire des corrélations.
Dans tous les cas, n’envoyez pas vos informations vers un serveur syslog perdu et dont vous aurez oublié l’existence dans les prochains mois ; envoyez les plutôt vers un espace centralisé, d’où il sera possible de tirer une forme de valeur.
Monitoring is so important that our monitoring systems need to be more available and scalable than the systems being monitored.
– Adrian Cockcroft
The DevOps Handbook (p. 200) Create Telemetry to enable seeing and solving problems
Selon le volume et la structure des données, il peut y avoir plusieurs solutions :
- Les métriques sont souvent stockées dans une Time Series Database (TSDB), spécialisée dans le stockage d’informations horodatées. Ce type de base de données s’occupe également d’appliquer un squash ou roll up sur une fenêtre de données, afin de limiter la quantité de données à maintenir. Ceci permet par exemple de stocker une valeur toutes les secondes sur les 24 dernières heures, d’appliquer une moyenne pour chaque période de cinq minutes sur les 3 derniers jours - cela donne 86400 points pour les dernières heures, et seulement 864 valeurs pour les trois derniers jours.
- Les logs sont stockés soit sous forme de fichiers, soit passés dans un indexeur - type ElasticSearch.
⚠️ Il n’est pas nécessaire de conserver les métriques (ou les logs) sur une longue période. Réfléchissez à définir une période de rétention - surtout pour éviter de stocker 365 jours d’utilisation de CPU, à raison d’une collecte toutes les dix secondes 😉. Les TSDB implémentent généralement ce comportement au travers d’un algorithme de roll up ou de squash, qui permet d’applatir une période au travers d’une seule valeur statistique. Ceci permet par exemple de stocker 86400 valeurs différentes sur les 24 dernières heures, mais seulement 864 à raison d’une moyenne par fenêtre de cinq minutes sur les 3 derniers jours.
Conserver des données ouvre de nombreuses possibilités dans la détection des problèmes, au travers de l’utilisation de statistiques. Anciennement, Nagios n’enregistrait pas la valeur reçue - il n’y avait donc aucune possibilité de repérer une tendance ; plutôt que de s’ancrer à ce mode de fonctionnement, un découplage en deux fonctions séparées est une étape (relativement) facile, notamment via l’utilisation de CollectD :
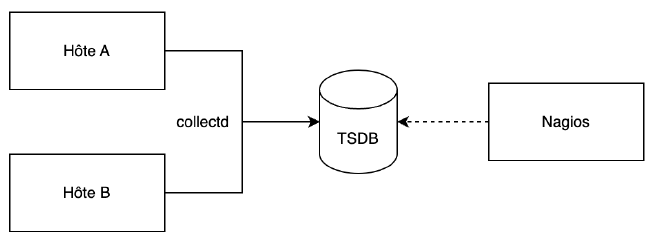
Pour une TSDB, voir Graphios ou pnp4Nagios.
Visualisation #
La visualisation transforme les données collectées et stockées en quelque chose de plus graphique. Disposer de tonnes de données n’est utile que si vous pouvez donner du sens à ces informations. Ce point amène à l’une des pilliers fondateurs d’un bon monitoring : construisez et assemblez des choses de manière à ce qu’elles s’intègrent bien à votre environnement. Les meilleurs tableaux de bord se concentrent exclusivement sur un service en particulier ; n’avoir qu’un seul tableau de bord est utopique.
Si vous utilisez un système statique comme Nagios, vous serez sans doute limité par son système de dashboarding. Si vous utilisez un système composable, vous pourrez vous tourner vers des logiciels comme Grafana ou Smashing. Pour aller plus loin sur ce sujet, l’auteur conseille The Visual Display of Quantitative Information d’Edward R. Tufte.
La visualisation (et l’analyse, plus bas) utilise quelques notions de statistiques :
- Moyenne arithmétique (couplée avec une notion de lissage, pour éviter d’avoir 60 valeurs pour 60 secondes). Le lissage permet de gagner en visualisation ce que nous perdons en précision. Il s’agit de la manière la plus classique de travailler sur des données de monitoring. Lorsque la moyenne n’est pas assez précise, envisagez de passer sur la médiane.
- Saisonnalité, pour visualiser les évolutions en fonction du temps (et de confirmer des modèles qui sortiraient de la normalité). A priori, regardez les journaux de trafic, et vous devriez y trouver une saisonnalité :
-
Quantiles, pour diviser les jeux de données en intervalle de même probabilité. Nous allons surtout regarder les percentiles p50 (la médiane) et p95.
-
Déviation standard (qui fonctionne seulement dans le cas d’une distribution normale) - sauf qu’il est très peu probable que nos données suivent une norme 😉 - surtout dans le cas d’incidents.
Analyse et reporting #
Dans certains cas spécifiques, la visualisation n’est pas suffisante, et il est nécessaire d’aller un chouia plus loin, notamment pour définir (et discuter) des Service-level Agreement (SLA). Un SLA est un contrat (un peu cynique) entre deux entités - un SLA sans pénalité peut être considéré comme un objectif à atteindre. Pénalité ou pas, la plateforme de monitoring doit être suffisamment complète et précise que pour présenter un rapport de disponibilité de vos services.
⚠️ Le théorème d’échantillonnage de Nyquist-Shannon affirme que La représentation discrète d’un signal exige des échantillons régulièrement espacés à une fréquence d’échantillonnage supérieure au double de la fréquence maximale présente dans ce signal. Pour mesurer une interruption à la seconde près, il sera nécessaire de descendre à une fréquence plus petite que la seconde. Atteindre un SLA de 99.999% sur une période d’un mois (arrondi à 43 800 minutes) implique d’avoir une indisponibilité de 26.28 secondes maximum.
Entre les recherches grep et les outils de statistiques type
Splunk, il y a toutes une série de points intermédiaires.
Pour démarrer, concentrez vous sur les réponses HTTP, le nombre d’utilisations de sudo, les logins en SSH, les résultats des cronjobs et les requêtes lentes en bases de données.
Perspectives utilisateurs #
Les utilisateurs se fichent des détails d’implémentation de votre application. Pour se concentrer avant tout sur ce dont les utilisateurs ont besoin ou qu’ils utilisent le plus, le plus simple consiste à mettre en place la surveillance de codes HTTP de certaines pages et de la latence de vos applications. Cette approche permet de ne plus avoir à penser en termes d’infrastructure physique, mais bien en termes de besoins utilisateurs : si un service venait à ne plus être disponible, mais que cette indisponibilité n’impactait pas les utilisateurs, c’est qu’il n’est pas réellement nécessaire d’y consacrer du temps.
Ainsi, ajouter une métrique revient à mesurer l’impact qu’elle pourrait avoir sur les utilisateurs (et avant d’ajouter quoi que ce soit de nouveau, nous nous demanderons pourquoi cela doit être ajouté 😉).
Le mode de fonctionnement et les choix que d’autres équipes ou entreprises peuvent avoir faits, pourraient ne pas fonctionner dans votre cas. Il est important de réfléchir à ce que “fonctionne” signifie pour l’utilisateur, plutôt que de collecter des métriques potentiellement inutiles :
- La première vérification pour une application Web peut être de s’assurer qu’on a bien un code HTTP 200 sur la page d’accueil ou qu’un texte spécifique est bien présent,
- Les métriques liées au système d’exploitation peuvent ne pas être utiles (- tout du moins pour de l’alerting) : si le taux d’utilisation du CPU est haut, mais que le serveur fait ce qu’il est supposé faire et que les utilisateurs ne se plaignent pas, il n’y a en fait pas de problème. A moins d’avoir une raison d’alerter sur les métriques systèmes, ne le faites pas : ce sont généralement des alertes bruyantes, qui seront souvent ignorées.
L’objectif est d’éviter d’appliquer une todo list ou de simplement recopier ce qui fonctionnerait pour d’autres groupes, sous prétexte que “si cela fonctionne pour eux, cela fonctionnera pour moi”.
Alerting #
Monitoring is for asking questions
– Dave Josephsen
S’il y a une partie du monitoring à réaliser correctement, ce sont les alertes. Sans les alertes, nous pourrions nous contenter de regarder des graphiques à longueur de journée, en attendant de trouver quelque chose d’anormal. Les bonnes alertes sont difficiles à mettre en place, et démarrer une alerte sur base de données brutes a tendance à créer des faux-positifs. Or, comme les alertes sont à destination d’humains, et que les humains ont une attention limitée, il convient de distinguer deux types :
- Les alertes “FYI” : elles ne requièrent aucune attention immédiate, mais quelqu’un doit être informé qu’un évènement a été détecté. Il s’agit ici plutôt de messages que d’alertes.
- Les alertes nécessitant une action immédiate, sans quoi un système va être rendu indisponible. Au besoin, il est nécessaire que quelqu’un intervienne, même au milieu de la nuit.
Quelques conseils :
- N’utilisez pas les emails pour les alertes. Un email n’a jamais réveillé personne. C’est une notification qui nécessite une action humaine.
- Si une action immédiate est nécessaire, passez par un service type PagerDuty.
- Si une information doit être communiquée, envoyez la vers une chat-room interne.
- Enregistrez vos alertes à des fins d’historisation et de diagnostics.
- Pour chaque alerte, incluez un lien vers un runbook d’actions à prendre. Ceci implique de pouvoir associer un comportement à une procédure (ce qui n’est pas toujours facile ou possible).
- Si les actions détaillées dans les runbooks peuvent toutes être automatisées, automatisez-les.
Arbitrary static thresholds aren’t the only way #
Les alertes basées sur des données ponctuelles (et relativement statiques) ne fournissent généralement pas de bonnes informations. Dans le cas où nous plaçons une alerte sur “Il nous faut un espace disque disponible de minimum X%” ne sera pas utile (surtout lorsque l’espace disque utilisé passera de 11% à 80% en une nuit), puisqu’on n’aura pas le temps de constater l’accroissement rapide d’un contexte. De la même manière,
- Si l’échantillonage est insuffisant et si le seuil subit un dépassement, puis qu’il revient à la normale, il ne sera pas intercepté,
- Si un seuil est (faiblement) dépassé, puis revient à la normale, puis est à nouveau au dessus de la limite, les alertes deviendront bruyantes.
- Il arrive qu’un système se comporte de manière inattendue, mais réagisse tout à fait correctement (du point de vue de l’utilisateur).
Utiliser un pourcentage d’évolution constaté permettrait par exemple de gérer correctement le cas ci-dessus, en indiquant que “L’espace disque disponible a été réduit de 50% durant la nuit”.
Noisy alerts #
Les alertes qui génèrent du “bruit” engendrent une perte de confiance auprès de ses utilisateurs, qui auront tendance à ne plus surveiller correctement les données qui leur sont transmises, voire à les ignorer totalement. Tout ceci pourra également mener à une fatigue plus généralisée, alors qu’une alerte est justement sensée donner un petit coup d’adrénaline.
Pour se débarrasser des alertes bruyantes :
- Vérifier si chaque alerte nécessite une intervention humaine. Si pas, voir si cette action peut être automatisée.
- Regarder l’historique des alertes émises le mois dernier, et vérifier si elles sont toutes nécessaires et quels en ont été les impacts. Regardez si le seuil de déclenchement peut être modifié, voire si l’alerte peut ne pas simplement être supprimée.
On-call #
Après plusieurs fois à être réveillé par des faux-positifs, des alertes un peu floues et à faire de l’IT-pompier, on commence à entrevoir les effets d’un burn-out : irritabilité, privation du sommeil, anxiété, …
Pour éviter ceci,
- Il est du devoir de la personne de garde travailler sur la résilience des systèmes et leur stabilité - lorsqu’elle n’est pas en train d’éteindre des incendies 😉
- Après un incident, exigez que les tâches améliorant la résilience et la stabilité fassent partie des priorités du prochain sprint.
- Faites en sorte d’avoir une rotation des gardes qui soit équitable - si vous avez quatre personnes, que chacune d’entre elles se succèdent selon un tourniquet (round-robin). Dans des entreprises internationales, il est aussi possible de suivre la rotation du soleil, en suivant les différents fuseaux horaires, pour assurer facilement une permanence H24.
Il est important que la personne de garde ait le comportement adéquat : être sobre, garder une connexion à distance disponible endéans un certain laps de temps, … Proposez que chaque période soit systématiquement suivie d’un jour off, et que les personnes de garde disposent d’une compensation financière.
Incident management #
La gestion des incidents est une manière normale de gérer les questions et problèmes qui surgissent. Il existe des frameworks comme ITIL, structurant les différentes étapes de manière séquentielle (comme l’identification de l’incident, son enregistrement, sa catégorisation, sa prioritisation, son diagnostic, prévoir une escalade (si nécessaire) vers le niveau 2, sa résolution, sa clôture et la communication de chacune de ces étapes vers l’ensemble des personnes), que l’on pourrait synthéthiser comme ceci :
- Identification de l’incident (le monitoring identifie un nouveau problème),
- Enregistrement de l’incident (le monitoring crée automatiquement un nouveau ticket de suivi),
- Diagnostic, catégorisation, résolution et clôture (la personne de garde dépanne, fixe le problème et résout le ticket avec le maximum de commentaires et de données complémentaires),
- Communication au travers de l’ensemble des étapes ci-dessus,
- Définir un plan de remédiation pour améliorer la résilience.
Cette cinquième étape mène vers une culture des post-mortems, qui est l’un des pilliers de l’amélioration continue.
⚠️ Une application mal écrite restera mal écrite, même avec de la surveillance.
Configuration manuelle #
S’il n’est pas possible d’ajouter rapidement une nouvelle vérification ou un nouveau noeud, le monitoring deviendra rapidement une plaie. Dans la mesure du possible, il doit être automatisable (et automatisé) - surtout dans une infra cloud-native.
Ce principe doit également s’appliquer aux cahiers d’exécution, à appliquer en cas d’incidents : si ces cahiers ne contiennent que des séries de commandes à entrer manuellement, automatisez-les !
Stratégies #
Il existe différentes stratégies sur ce qu’il est nécessaire de surveiller (et comment le mettre en place). Ces stratégies concernent le métier, les frontends, les applications, le réseau et les serveurs.
Monitoring du métier #
Est-ce que le site est accessible ? Est-ce que des utilisateurs sont impactés ?
Ce point consiste à surveiller la santé des domaines métiers : est-ce que les utilisateurs ont la possibilité d’utiliser nos services, est-ce qu’il y a de l’argent qui rentre (et combien), est-ce que la progression est bonne (ou pas), est-ce que les utilisateurs sont satisfaits ? Quelques métriques sont proposées :
- Les revenus mensuels,
- Les revenus par utilisateur,
- Les coûts par utilisateur,
- Le nombre d’utilisateurs actifs,
- Le coût d’acquisition d’un nouvel utilisateur,
- Le Total Addressable Market, où la taille totale du marché si notre produit était vendu à l’ensemble des personnes potentiellement intéressées,
- …
Une fois que ces métriques sont définies, il est possible de les lier à des fonctionnalités proposées/offertes par nos services applicatifs. L’étape d’après consiste à lier ces métriques métiers à des métriques techniques, afin d’avoir une meilleure idée des problèmes qui pourraient survenir. Il est donc nécessaire de réfléchir à intégrer nos processus de contrôle directement dans nos systèmes. Pour cela, il est recommandé de monitorer qui accède à quelle fonctionnalité.
Frontend monitoring #
Le frontend, c’est un peu l’angle mort du monitoring. Le composant que l’on oublie souvent, mais qui est pourtant le principal (et parfois, le seul) point d’entrée des utilisateurs.
Une étude datant de 2010 indiquant qu’un délais d’une seconde (supplémentaire) dans le chargement d’une page Web équivalait en moyenne à une perte de 11% par rapport au nombre de pages vues et à 16% de baisse de la satisfaction utilisateurs. Amazon et Shopzilla sont arrivés à des conclusions similaires lorsque le temps de chargement des pages est passé de 6 secondes à 1.2 secondes : les revenus ont augmenté de 12%, les pages vues de 25%, alors qu’Amazon indiquait une amélioration d'1% du revenue pour chaque 100ms gagnées.
Le chargement d’une page Web est de maximum (et c’est déjà beaucoup) 4 secondes. Des APM comme Sentry permettent de visualiser clairement les users miseries, latences, p50 et p95.
A noter qu’un moyen simple pour diminuer le temps de chargement consiste à baisser le nombre de dépendances 😉
Application monitoring #
Le monitoring applicatif est une étape relativement intrusive, qui consiste à surveiller le temps que prend chaque action, appel à une base de données, temps de réponse de l’API d’un fournisseur, … Le monitoring applicatif et le frontend sont deux étapes complémentaires : disposer du temps d’exécution d’une fonction ne donne cependant pas d’indications sur l’ensemble du chemin - chemin que l’utilisateur ne verra pas (lui, il verra juste que sa page met longtemps à charger).
L’auteur conseille d’utiliser StatsD :

import statsd
statsd_client = statsd.StatusClient("localhost", 8125)
def login():
login_timer = statsd_client.timer("app.login.timer")
login_timer.start()
statsd_client.incr("app.login.attempts")
if password_is_valid():
statsd_client.incr("app.login.successes")
render_template("welcome.html")
else:
statsd_client.incr("app.login.failures")
render_template("login_failed.html", status=403)
login_timer.stop()
login_timer.send()
Le monitoring applicatif consiste également à surveiller les pipelines et déploiements. Il est intéressant ici d’agréger le temps qu’un déploiement a pris (quand il a démarré), le nombre de releases d’une application, qui a déclenché le déploiement, … Etsy a popularisé ceci sous le moto “Measure anything, measure everything”. Avoir ce type de métriques intégrées aux autres données permet d’avoir une corrélation directe entre une nouvelle release et un gain significatif sur certains temps de réponse.
Un autre conseil consiste à développer systématiquement (lorsque c’est possible) un endpoint de type /health.
Celui-ci a pour objectif de donner un statut de l’état des composants utilisés :
from django.db import connection as sql_connection
from django.http import JsonResponse
import redis
def check_sql():
try:
with sql_connection.cursor() as cursor:
cursor.execute("SELECT 1 FROM table_name")
cursor.fetchone()
return {"okay": true}
except Exception as e:
return {"okay": false, "error": e}
def check_redis():
try:
redis_connection = redis.StrictRedis()
result = redis_connection.get("test-key")
...
except Exception as e:
return {"okay": false, "error": e}
def health():
if all(check_sql().get("okay"), check_redis().get("okay")):
return JsonResponse({"status": 200}, status=200)
return {
"mysql_status": check_sql(),
"redis_status": check_redis()
}
Si nous devons réaliser une interrogation vers un service extérieur, il suffit d’ajouter une fonction qui interrogera le statut de ce service également. Cet endpoint demande un peu de travail et de maintenance, mais peut rendre de grand service - surtout en étant couplé avec le reste de la plateforme de monitoring.
Jusqu’à présent, nous avons parlé de monitoring de métriques, mais il reste également les journaux d’évènements. Le problème des logs est que la volumétrie est beaucoup plus importante que pour les métriques :
# métrique
app.login_latency = 5
# log
{
"app_name": "foo",
"login_latency": 5,
"user": "Julian",
"success": false,
"error": "login failed"
}
Un évènement contient de facto beaucoup plus d’informations…
Mais peut contenir des métriques également 😌
Il est également conseillé de tout logger…
Mais tout en restant 🤭 et potentiellement, en utilisant les niveaux de journalisation - qui permettraient (temporairement) de switcher d’un niveau ERROR à un niveau DEBUG, afin de mieux comprendre un contexte.
Il est également conseillé que les logs soient écrits sur disque - pour ne pas saturer le réseau - quitte à être lus par un daemon qui viendrait lire les données les plus récentes à intervalle régulier.
En cas de coupure réseau, nous gagnerons en stabilité.
Si vous disposez d’une architecture orientée services (ou micro-services), pensez à ajouter un identifiant de tracing sur vos requêtes, pour pouvoir suivre chaque requête au travers de ses différents composants.
Server monitoring #
Les valeurs les plus simples à monitoring sont la consommation mémoire, l’espace disque et le taux d’utilisation du CPU. Comme nous l’avons vu plus haut, ces données peuvent ne pas être pertinente sur le service est toujours accessible et si les utilisateurs ne sont pas impactés : ce sont surtout les écarts brutaux qui doivent être tenus à l’oeil. Un point critique concerne cependant l’expiration des certificats : au besoin, un script shell peut servir à compenser un paquet de certificats internes.
Let me put this in no uncertain terms : stop using SNMP for servers (see page 98 & 112). Rather than using SNMP, opt for a push-based tool like collectd, Telegraf or Diamon.
Le monitoring des serveurs implique également de monitorer les composants hébergés sur ces serveurs : bases de données, load balancers, messages queues, caching, DNS, NTP, …, DHCP, SMTP, …
Les scheduled jobs peuvent devenir un point délicat à gérer : comment monitorer des tâches planifiées, où l’absence d’une donnée indique que quelque chose a mal tourné ? Une manière de gérer ceci consiste à créer une information là où il n’y en avait pas auparavant :
run-backup.sh 2>&1 backup.log || echo "Job failed" > backup.log
Ce dont nous avons, c’est quelque chose qui détecte quand des données n’apparaissent pas. Cette situation est intitulée dead man’s switch, et peut être implémentée de la manière suivante :
#!/bin/sh
TIME_LIMIT=$((60*60))
STATE_FILE=deadman.dat
last_touch=$(stat -c %Y $STATE_FILE)
current_time=$(date +%s)
timeleft=$((current_time - last_touch))
if [ $timeleft -gt $TIME_LIMIT ]; then
echo "Dead man's switch activated: job failed!"
fi
Security monitoring #
Le problème de la sécurité est qu’on ne sait pas précisément quoi surveiller.
Une proposition consiste à utiliser auditd pour suivre (entre autre) :
- Toutes les exceptions
sudo, la commande qui a été exécutée, et qui l’a demandée, - Les accès aux fichiers et les changements sur certains fichiers en particulier,
- Les tentatives de connexion et les échecs (de connexion).
Il est aussi question de Host Intrusion Detection System (HIDS) avec rkhunter et de Network Intrusion Detection System (NIDS), qui nécessitent de placer des network taps - à condition de pouvoir monitorer ces taps et de s’assurer qu’ils sont bien up and running.
Pour résumer #
- Composable monitoring » Monoliths,
- Monitor from the user perspective,
- Opt for buying tools,
- Always look for improvments,
- Write runbooks,
- Not every alert can be boiled down to a simple threshold,
- Attempt automatic self-healing,
- Improving the on-call experience isn’t too difficult with a few tweaks,
- Building a simplified and usable incident management process for your company, should be prioritized,
- Instrumening applications with metrics and logs is one of the most impactful-thing you can do to understand and troubleshoot application performances,
- Track releases and correlate them with performances,
- The
/healthendpoint is pretty neat, - Serverless and microservices monitoring isn’t that different from any other application,
- Do not use SNMP,
- Use TCP instead of UDP.