Leadership is about managing uncertainty, bringing order to chaos, providing hope for a better future and progressing toward that future
– Napoleon Bonaparte
L’architecture peut être présentée en trois couches :
- La couche métier (business) : elle croque les opérations et montre comment les composants travaillent ensemble pour que le métier fonctionne comme attendu.
- Le système d’informations, qui regroupe les données et les applications. Il catégorise les types de données et souligne leurs connexions, et décrit les services et leurs liens avec le système dans sa globalité.
- La couche technologique : quelles sont les technologiques qui ont été choisies, les standards informatiques et de développement, les paquets logiciels, le matériel, le réseau et la sécurité.
L’objectif d’une architecture logicielle consiste à construire des systèmes qui rencontrent la qualité attendue par les standards et qui fournissent le plus haut retour sur investissement à long terme. Les incertitudes suivantes compliquent une architecture :
- Le comportement des utilisateurs (et la compréhension qu’ils ont du système),
- La compréhension limitée de la manière dont les composants système interagissent entre eux,
- Au fur et à mesure que les utilisateurs et les utilisations changeront, leurs exigences évolueront avec eux.
Les solutions consistent à :
- Prendre les décisions le plus tard possible,
- De concevoir une modélisation qui soit la plus facile à comprendre et à modifier,
- De refuser (autant que possible) les demandes de nouvelles fonctionnalités et de modifications.
L’architecture est une affaire de compromis, en fonction d’un contexte actuel (et temporel) et d’un ensemble d’informations dont nous disposons. D’autre part, l’expérience montre que le délai de mise à disposition sont souvent non-négotiables ; les fonctionnalités à ajouter à chaque nouvelle version (ou itération) sont celles qui apportent la plus grande valeur au plus grand nombre d’utilisateurs (et avec le moins d’effort). Soyez humble : concevez un système qui fonctionne pour 10k à 50k utilisateurs, et faites-vous à l’idée qu’il sera nécessaire de le réécrire entièrement lorsque le moment sera venu.
Principes d’architecture #
- Partez systématiquement d’une demande ou d’un problème rencontré par un utilisateur. La plus grande source d’erreur dans une architecture concerne les fonctionnalités qui sont (rarement ou totalement) utilisées, et qui impliquent un gâchis de temps et d’argent. Demandez toujours :
- Comment la demande va-t-elle affecter le trajet de l’utilisateur,
- Quelle valeur cela va-t-il ajouter,
- S’il y a quelque chose d’autre qui ajouterait de la valeur à cette demande.
- Découpez le système le plus finement possible. Créez uniquement des fonctionnalités qui vont de bout en bout et qui sont utiles à chaque itération, n’écrivez que du code qui soit le plus simple possible et n’optimisez que si cela s’avère nécessaire. L’auteur indique que c’est ce qui a (notamment) permis au frères Wright d’aussi bien démarrer dans l’aviation : partir d’une solution fraîche et procéder par petit incrément rapide, plutôt que de partir d’une solution complexe et potentiellement grévée de biais cognitifs.
- A chaque itération, n’ajoutez que ce qui apporte le plus de valeur au plus d’utilisateur (et avec le moins d’effort), en faisant attention aux demandes farfelues des utilisateurs : Henry Ford disait que “S’il avait demandé à ses clients ce qu’ils souhaitaient, ils auraient demandé des chevaux plus rapides” (même si on n’est pas tout à fait sûrs que ce soit lui qui ait dit ça).
- Lorsque c’est possible, utilisez des services existants, type middlewares ou services Cloud. Ceci diminue le temps nécessaire à mettre à disposition un ensemble de fonctionnalités qui n’aurait pas obligatoirement de plus-value - tout en gardant un bon niveau de sécurité (un fournisseur spécialisé en sécurité aura toujours un meilleur niveau de qualité que si vous deviez le développer vous-mêmes).
- Prenez les décisions et absorbez-en les risques. Il est nécessaire de retirer toute ambigüité et de créer des objectifs qui soient réalisables et concrets.
- Prenez le temps de réfléchir en profondeur aux éléments qui seront difficiles à modifier par la suite et implémenter les lentement (et qualitativement). Ceci permet par exemple de masquer les détails d’implémentation, qui peuvent alors être mis en place plus tard. Il s’agit typiquement des éléments suivants :
- Des API exposées aux utilisateurs,
- Des API associées à des services partagés,
- Des schémas de bases de données,
- Des données partagées et des formats d’échange,
- Des différentes technologies et frameworks utilisés.1
-
Eliminez tout ce que vous ne comprenez pas et apprenez des preuves en travaillant dès que possible sur les problèmes difficiles, et en parallèle. Ajoutez du monitoring au plus vite et sur tous les éléments qui pourraient poser des problèmes ultérieurement, et prenez le temps de tout instrumentaliser : métriques systèmes, taille des files d’attente, bande passante, traces applicatives, … et aux différents couches de votre écosystème.
Services decomposition #
Une architecture typique - quel que soit le domaine d’application - se constitue de plusieurs services généralement découplés et interfacés les uns avec les autres. La décomposition des services consiste à séparer chaque service pour répondre à un ou plusieurs problèmes en particulier.
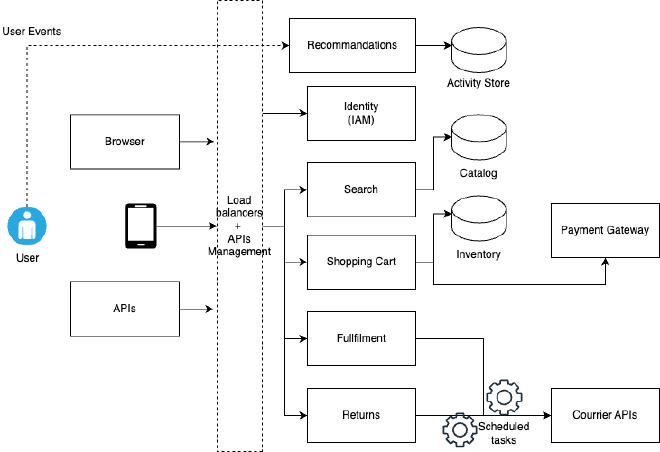
Une évolution possible consiste à faire basculer ces blocs vers des services Cloud, exposés par des plateformes externes. Cette (nouvelle) intégration peut être de deux types :
- Shallow Cloud Integration : Les services sont écrits de notre côté, empaquetés dans des containers et déployés sur des services hébergés sur le Cloud, mais en se limitant aux bases de données et aux espaces de stockage uniquement.
- Deep Cloud Integration : Les services existent et sont maintenus (et vendus) par différents fournisseurs, chacun sur leur propre plateforme. Ils remplacent les services développés en interne par des fonctionnalités serverless, avec des services Cloud ou des solutions de type SaaS.
Les APIs externes nécessitent cependant une attention particulière au niveau de la sécurité. En poussant cette réflexion un peu plus loin, il est facile de considérer chaque API comme externe au reste de l’écosystème ; ceci permet de pousser la sécurité à son paroxysme, en visant un environnement Zero Trust, où chaque action nécessite l’utilisateur à s’authentifier.
Performances système #
Le paradoxe de l’architecture se situe au niveau des performances : d’un côté, nous essayons de construire des systèmes maintenables et faciles à comprendre, et de l’autre côté, nous devons conserver des objectifs de performances adéquats, en faisant rentrer l’application dans les contraintes techniques (CPU, RAM, disques, réseaux, processus et I/O, …).
User Experience (UX) #
L’UX ne se limite pas uniquement à l’ergonomie générale d’une application ou à sa facilité d’utilisation, mais touche en fait à tous les domaines auxquels l’utilisateur a accès, en ce compris les APIs, la configuration, la documentation ou les possibilités d’extension (= greffons) pouvant y être adjoints.
Un système proche de la perfection anticipe ce que vous pourriez souhaiter au moment où vous pourriez en avoir besoin. Pour cela, il est nécessaire :
- De comprendre les utilisateurs, en proposant des points d’extension pour les geeks, des exemples de scripts pour les développeurs et une bonne UI pour les utilisateurs plus techniques.
- De faire aussi peu que possible, en n’implémentant que les fonctionnalités qui sont réellement nécessaires. Même si vous offrez une expérience “presque parfaite”, la suppression d’une fonctionnalité sera toujours extrêmement compliquée dans la mesure où certains utilisateurs y seront déjà attachés.
- Un bon produit n’a pas besoin de mode d’emploi.
- Réfléchissez en termes d’échanges d’informations : comme il n’est pas possible de deviner les intentions d’un utilisateur, il convient de fournir autant que possible des valeurs par défaut qui soient cohérentes, de manière à ce que les utilisateurs aient le moins de données à encoder par eux-mêmes.
- Faites en sorte que les choses simples restent simples.
De manière générale, concevez l’UX avant l’implémentation : évitez autant que possible de rendre une configuration complexe ( La configuration de Gitea par exemple est bourrée de valeurs par défaut est relativement brain-friendly). Dans tous les cas, documentez systématiquement quelques exemples, accompagnés des valeurs possibles et du sens que vous leur avez donné.
Macro Architecture #
Une macro-architecture voit les systèmes comme des unités - qui peuvent être autant des composants que des services. Chaque fonctionnalité qui ne peut pas être représentée en utilisant l’un de ces blocs de conception (building blocks), par exemple les load balancers, outils ou middlewares, sera implémentée comme un service. Chacun de ces services couvrira certaines caractéristiques ou fonctionnalités qui ne pourront être réutilisées comme des building blocks. Une des pistes de stratégies consistera à choisir entre une architecture orientée services (SOA) ou une architecture orientée ressources (ROA).
Chronologiquement, nous avons vu l’évolution de ces architecture :
Modern Architecture #
Une architecture moderne se compose des éléments suivants :
- Data management : bases de données, caches distribuées et registres.
- Routeurs et messaging : reverse proxies, load balancers, API managers, Enterprise Service Bus (ESB), messages brokers.
- Executors : systèmes de workflows, map/reduce, containeurs, machines virtuelles.
- Security : serveurs d’IAM ( WSO2, …).
- Communication : DHTs, Gossip Protocol, Distributed Coordination, …
- Autres composants : gestion des transactions ( Atomikos, …), …
Il existe plusieurs manières de coordonner les échanges d’informations ; en général, piloter le flux d’informations à partir des désidérata de l’utilisateur est suffisant. Il est également possible d’utiliser des méthodologies (type Choreography, Centralized Middlewares ou services externes), mais celles-ci viennent avec leurs propres désavantages - et notamment la nécessité d’un monitoring intense de chaque ressource, pour suivre chaque avancée, récupération ou notification.
Sécurité #
Dans une architecture moderne, la sécurité est un point critique qui doit être pris au sérieux à toutes les étapes de la mise en application, la base de tout ceci étant le renouvellement des certificats et le support SSL/TLS. Il convient dès lors de :
- Sécuriser l’ensemble des points de communication avec le monde extérieur,
- Gérer correctement les utilisateurs,
- S’assurer que seuls les utilisateurs autorisés peuvent réaliser certaines actions sur les systèmes de données et ressources qui appartiennent à l’organisation.
La sécurité est un domaine trop complexe que pour être réimplémentée par n’importe qui.
If you choose to start from scratch, you will end up investing a lot of time and still not getting it right (Page 85)
La gestion des utilisateurs implique de gérer les méthodes d’authentification, les écrans de connexion, la fédération et les imprévus - type récupération de mot de passe. Elle implique également de gérer les traces d’audit, les niveaux d’autorisation et les clés de connexion. De manière générale, il existe quatre grandes catégories d’utilisateurs, chacune ayant son propre IAM :
- Le public (externe à l’institution),
- Les utilisateurs enregistrés, qui utilisent les services de l’institution (Customer IAM ou CIAM)
- Les utilisateurs internes à l’institution (Identity Access Management - IAM)
- Les administrateurs (Privileged Access Management - PAM).
En termes d’authentification, les anciens modèles envoyaient les mots de passe à destination du serveur, mais il s’agit d’une mauvaise habitude, puisque le serveur pourrait enregistrer et traiter ces informations. Les nouvelles tendances contactent un Identity Provider (Idp), type SAML ou OpenId Conect, au travers d’un échange de jeton :
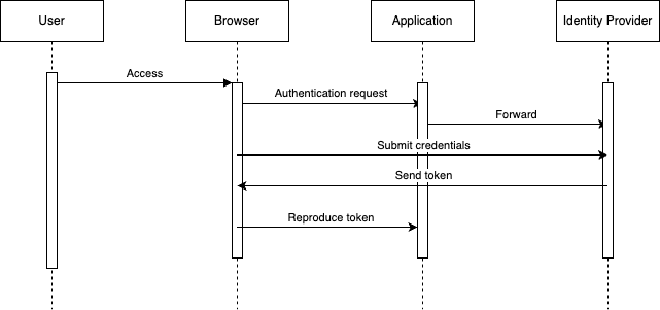
Anyone can design a security system that you yourself can’t think of a way of breaking. That doesn’t mean it works, it just means that it works against people stupider than you."
Authorization #
Une vidéo de Sam Scott explique pourquoi l’authentification est compliquée.
Les principales manières de gérer les autorisations se font sur les modèles RBAC (Role Based Access Control) ou ReBAC (Relationship Based Access Control) - qui est une évolution du premier, permettant surtout de contrôlersur quels éléments un utilisateur peut effectuer un ensemble d’actions - là où RBAC ne permet que de donner un accès ou des permissions à l’ensemble des éléments d’un même type.
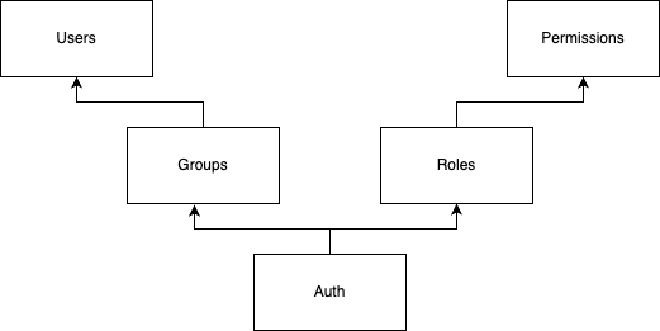
Si RBAC est suffisant pour vous, utilisez-le.
Stratégiquement, s’il existe un service externe qui couvre l’ensemble de vos besoins et qui peut être déployé en une fois, utilisez-le, plutôt que de (re)construire une solution graduellement. Un système présentant une solution naïve n’est généralement pas une bonne solution. Mais d’un autre côté, remplacer un IAM ou CIAM va clairement être ardu.
Storage & GDPR #
Le principal risque avec le GDPR, ce sont les employés qui partageraient des données sensibles. Le GDPR exige que les données d’identification (Personal Identifiable Information - PII), telles que les numéros de registre, numéros de cartes d’identité, adresses emails, soient sécurisées. En termes de sécurité, il est conseillé de ne conserver que ce qui est réellement nécessaire (principe de least knowledge) ; il est également conseillé de séparer les données sensibles (de manière chiffrée, si possible) des autres informations.
Une manière (considérée comme bonne…) consiste à accéder aux données grâce à des UUID, puis à les stocker au niveau de l’IAM.
Zero-trust #
Dans un environnement Zero-Trust, les utilisateurs sont continuellement authentifiés, autorisés et validés, à chaque étape ou transaction qu’ils effectuent. Historiquement, les utilisateurs était automatiquement approuvés dès lors qu’ils se trouvaient dans le périmètre de sécurité de l’institution ; cependant, la surface d’attaque a continuellement augmenté - notamment avec l’introduction des BYOD, IoT et APIs. Le besoin en sécurité apparait de plus en plus évident à plusieurs endroits d’une infrastructure, et avec un minimum de privilèges, afin de limiter le Blast Radius.
High availability #
Il y a deux manières principales de proposer de la haute-disponibilité :
- Réplication,
- Fast-recovery.
La réplication est mise en place en conservant des copies distinctes mais synchronisées (et à jour) d’un ensemble de données, derrière un répartiteur de charge. Les répartiteurs hardware sont les plus fiables ; après quoi vient l’IP Hot Swap. Si ni l’un, ni l’autre ne sont disponibles, passez par un package type keepalive sur un environnement Linux.
Un des problèmes lié à la répartition concerne le maintient des sessions : si une session devait être disponible sur l’un des systèmes, il est possible de passer par des sticky sessions - soit au travers d’un stockage en base de données, soit en utilisant le local storage proposé par le navigateur.
La réplication consomme beaucoup de ressources (il est nécessaire d’avoir au moins 2n+1 noeuds) et que le débogage n’est pas le plus facile qui soit, il est intéressant de considérer le fast-recovery, mais il faut pour cela que :
- L’application ou l’environnement puisse se réinitialiser à un état stable en très peu de temps,
- Que l’ensemble des composants puisse redémarrer dans les 2-3 secondes maximum,
- Que l’application puisse récupérer l’état dans lequel se trouvait l’environnement précédent.
La haute-disponibilité se base également sur les concepts de mise à l’échelle verticale (on augmente la RAM, on ajoute un plus gros CPU, …) ou horizontale (on ajoute de nouvelles instances).
Writing services #
Ecrire des services est relativement facile en utilisant des technologies récentes. En cas de doute, le plus simple consiste à utiliser un modèle type “Un thread = une requête” (en faisant en sorte que chaque requête puisse être exécutée rapidement et en s’assurant qu’il n’y a rien de bloquant sur le chemin d’exécution). Faites également en sorte que chaque requête soit idempotent, éventuellement en échangeant des cycles CPU par de la mémoire, via l’utilisation d’une mémoire cache.
Un service peut être amélioré avec une architecture Event Driven (EDA) ou Staged Event Driven Architecture (SEDA). Ce point nécessite cependant une attention particulière, dans la mesure où la complexité qui est apportée peut ne pas valoir l’investissement. Mais il peut être nécessaire de rendre un service plus complexe qu’il ne l’est, pour allégrer la complexité de l’architecture dans son ensemble.
Building stable systems #
Un système stable est un système dont le comportement reste prédictible, qui remplit toutes ses spécifications (même sous une charge conséquente) et qui continue à fonctionner sous un mode dégradé si des conditions extraordinaires devaient se présenter : tout le monde préfère un système qui fonctionne moins bien pendant une courte période temps, qu’un système qui pourrait perdre ou corrompre ses données - même avec une probabilité très faible.
Known errors #
Les erreurs connues sont des erreurs qu’il est possible de gérer de manière méthodique.
- Charge inattendue : il suffit de dropper des requêtes en utilisant un code HTTP 503 - qui correspond à une forme de back-pressure -, en faisant de l’ auto-seeding, … Si ceci ne peut pas être géré de manière automatique, il est plus que probable que le serveur tombe très rapidement.
- La manière dont les utilisateurs interragissent : on peut mettre en place GitOps, des déploiements blue-green ou du canary testing.
- Des bugs communs : memory leaks, deadlocks, opérations lentes ou nécessitant trop de ressources, ou des mauvais comportements.
Unknown errors #
Pour palier aux erreurs inconnues, les solutions sont également multiples, mais la principale concerne l’Observability, en passant par un Application Performance Manager (APM) : au plus vous apprendrez à propos de vos systèmes, au plus vous réaliserez qu’il y a des choses que vous ne connaissez et ne comprenez pas. Un APM permet de suivre des métriques personnalisées (latences, bande passante, utilisation des ressources, …). A chaque fois que le système dévie d’une ligne de référence (initialisée manuellement), il sera nécessaire de réaliser une analyse.
Evolving the system #
The ennemy of agility is large and heavy build (page 167)
- Soyez sûr que la phase de construction de vos sources fonctionne sur n’importe quelle machine, et que les développeurs disposent de suffisamment de ressources que pour être rapidement efficaces - et qu’ils ne doivent pas passer plus de quelques heures à se construire un environnement générique et fonctionnel.
- Instaurez un environnement de pair programming, avec une culture de revue de code systématique.
- Ecrivez des bons tests unitaires.
- La roadmap est pilotée par les utilisateurs, pas par les développeurs.
- Chaque fois que vous dites “oui” à une fonctionnalité, vous dites “non” à plein d’autres.
- Exigez l’excellence de la part de vos équipes ; laissez-les expérimenter et concevoir en profondeur.
- Lorsque quelque chose ne fonctionnera plus, sondez jusqu’à en comprendre les causes. Ensuite, lorsque vous aurez répondu à ce qui peut être mis en place pour que cela n’arrive plus, faites en sorte que ces décisions soient suivies.
- Organisez des réunions bi-hebdomadaire d’architecture.
Business hates surprises. Although there will be (surprises), the key is to communicate them early and explain the sources.
Ressources (et conclusion) #
- https://github.com/ory/keto pour un modèle d’autorisations supportant les ACL et RBAC.
-
Modéliser vos APIs et formats de message le plus tôt possible, en gardant systématiquement la sécurité en ligne de mire. ↩︎